Unique Identifier
Unique ID’s in the US
Are you looking for a unique value to identify addresses in the USA? Here, we cover the pros and cons of USPS data and look at alternatives
Deterministic matching and probabilistic matching are the two main matching techniques used when clearing data duplicates.
Organizations store different types of data in different ways - from internal databases such as CRM systems to order management and other applications. In order for that data to be useful, it must be accurate. Examples of “bad data” include misspellings and typos, formatting errors, and duplicates. Data matching is a process used to improve data quality. It involves cleaning up bad data by comparing, identifying or merging related entities across two or more sets of data. Two main matching techniques used are deterministic matching and probabilistic matching.
Deterministic matching is a technique used to find an exact match between records. It involves dealing with data that comes from various sources such as online purchases, registration forms and social media platforms, among others. This technique is ideal for situations where the record contains a unique identifier, such as a Social Security Number (SSN), national ID or other identification number. When it’s not possible to determine a unique identifier, other pieces of an individual’s information (address, phone number, email address, etc.) are separately compared and then used together as required conditions to signify a match. This leads us to the next technique - probabilistic, or “fuzzy” matching.
Probabilistic matching involves matching records based on the degree of similarity between two or more datasets. Probability and statistics are usually applied, and various algorithms are used during the matching process to generate matching scores. In probabilistic matching, several field values are compared between two records and each field is assigned a weight that indicates how closely the two field values match. The sum of the individual field’s weights indicates a possible match between two records. The image below illustrates a fuzzy matching technique called the Levenshtein Algorithm, which is a string metric used to measure the difference between two sequences:
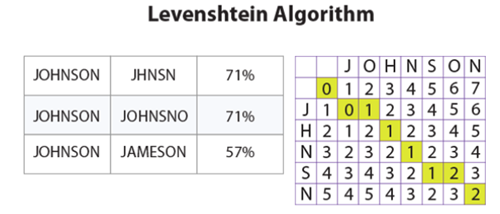
To put it simply, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into another.
Why Melissa?
Did you know 8-10% of an organization’s database contains duplicate records? Melissa’s global database supports both deterministic and probabilistic matching strategies to optimize matching routines. We apply advanced link analysis and entity resolution to our own data as well as our customers’ data to minimize duplicate matches. Our intelligent parsing capability parses various components of domestic and international addresses. Melissa’s MatchUp combines deep domain knowledge of contact data with over 20 fuzzy matching algorithms to match similar records and quickly dedupe your database, including proprietary ones like MD Keyboard and Proximity Matching.
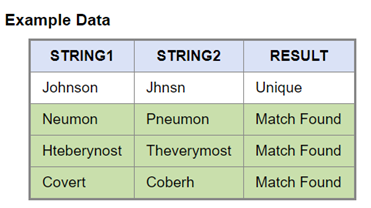
Melissa’s MD Keyboard is a typographical matching algorithm that counts keyboarding mis-hits with a weighted penalty based on the distance of the mis-hit and assigns a percentage of similarity between the compared strings. Thus two records with c > v or v > b typos are more likely to have an actual duplicate. The graphic below illustrates the type of data matched using this technique:
Proximity Matching, Melissa’s patented distance algorithm, enables distance criteria to be used in matching customer records, capitalizing on latitude, longitude, and proximity thresholds to help data managers eliminate duplicate records. This allows for the detection of matching records at different addresses but within a specified distance from each other. The graphic below illustrates this capability, showing how MatchUp can match buildings with different addresses by identifying different entrances common to large campus-style facilities:

MatchUp handles:
By identifying and eliminating duplicates, Melissa’s data matching solutions empower businesses with a more accurate, single customer view and helps them reduce costs and waste. Businesses also get a clearer picture of their pipeline with clean, reliable data for more effective analytics and reporting.
Are you looking for a unique value to identify addresses in the USA? Here, we cover the pros and cons of USPS data and look at alternatives
The USPS considers no-stats as inactive addresses that are unlikely to receive mail, and sending mail to an inactive address costs valuable time and...
The Early Warning System (EWS) flags streets not yet included in ZIP+4 reference data and makes sure that addresses are not inaccurately coded or...